Architectural Approach
The BDGlue architecture is modular in its approach, based on the idea of sources, encoders, and publishers, with the goal of mitigating the impact of change as new capabilities are added. For example, “encoders” are independent of their upstream source and their downstream publisher so that new encoding formats can be implemented without requiring change elsewhere in the code. The following diagram illustrates the high level structure of BDGlue.
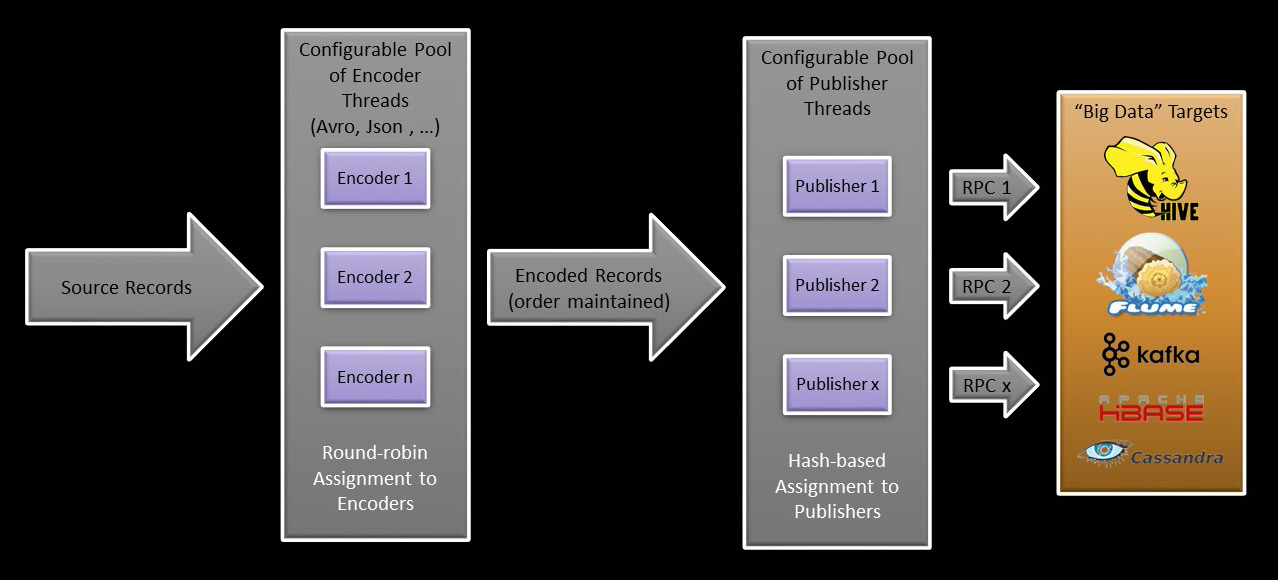
Encoding is the process of translating data received from the source into a particular format to facilitate downstream use. Publishing is the process of writing data to a target environment via RPC. You will note that BDGlue was designed to support two separate and distinct thread pools to provide scalability for the “encoding” and “publishing” processes, each of which can be somewhat time-consuming.
Note that while the process of encoding data is multi-threaded and essentially asynchronous, the encoded records are actually delivered to the publishers in the same order that they were received from the source. This is to ensure that data anomalies don’t get introduced as a result of a race condition that might arise if multiple changes to a particular record occur in rapid succession, but it will likely have a small impact on encoder throughput
In the same way, data is delivered to individual publishers based on a hash of a string value … either
-
the “table” name, ensuring all records from a particular “table” will be processed in order by the same publisher; or
-
based on the “key” associated with the record, in this case ensuring that records based on the same key value are processed in order by the same publisher.
The targets themselves are completely external to BDGlue. In most cases, they are accessed via an RPC connection (i.e. a socket opened on a specified port). A “target” might be a streaming technology such as Flume or Kafka, or it might be an actual big data repository such as HBase, Oracle NoSQL, Cassandra, etc. From Flume we can deliver encoded data at a very granular level to both HDFS files and Hive.
Last but not least in the BDGlue conversation has to do with sources. BDGlue was designed initially with the idea of delivering data sourced from a relational database, and leveraging Oracle GoldenGate in particular. We quickly came to realize that BDGlue had the potential of being more generally useful than that, so we made a deliberate effort to decouple the data sources specific to GoldenGate from the rest of BDGlue to the greatest degree possible. BDGlue looks at things from the perspective of table-like structures – essentially tables with a set of columns – but the reality is that any sort of data source could likely be mapped into them without requiring a lot of imagination or effort.