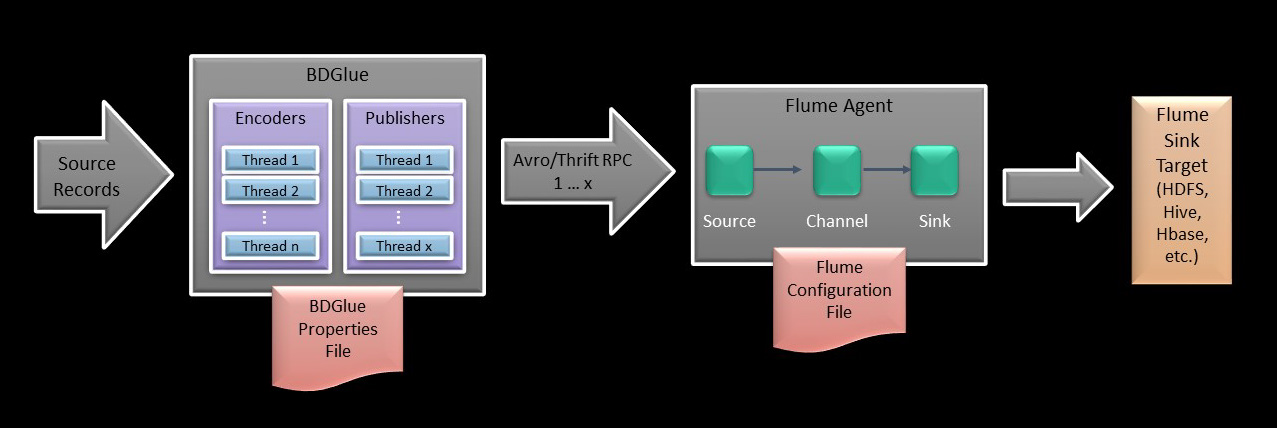
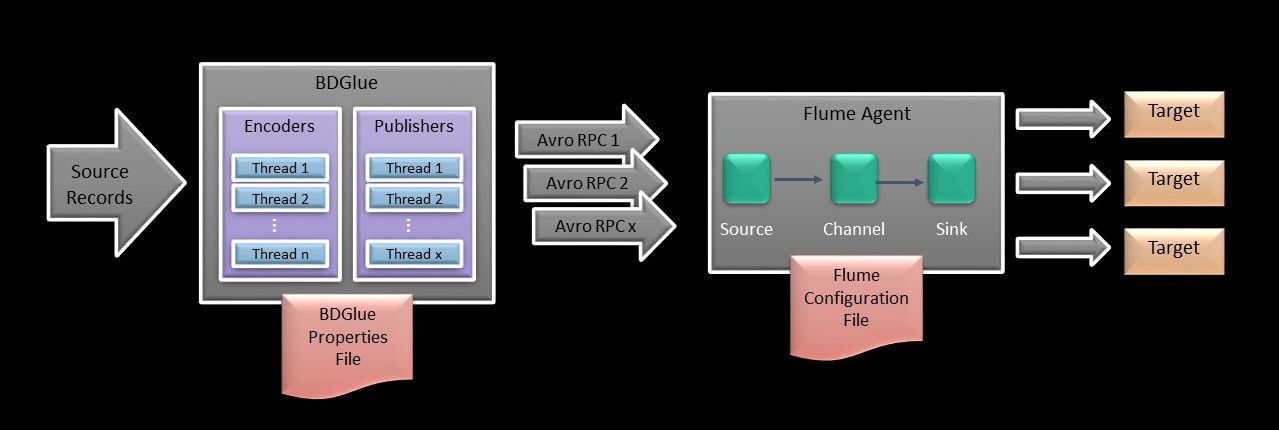
Apache Flume is a streaming mechanism that fits naturally with the BDGlue architecture. Flume provides a number of out-of-the-box benefits that align well with the BDGlue use case:
It supports RPC connections from locations that are not physically part of the Hadoop cluster.
It is modular and thus extremely flexible in terms of how data “streams” are configured.
There are many out-of-the-box components that can be leveraged directly without need for modification or customization.
In particular, Flume does an outstanding job with its HDFS file handling. If there is a need to stream data from outside of Hadoop into files in HDFS, there may be no better mechanism for doing this.
It provides a pluggable architecture that allows custom components to be developed and deployed when needed.
To really understand what is going on behind the scenes, it is important that the user have a good understanding of Flume and its various components.
A good reference on Flume is:
Apache Flume: Distributed Log Collection for Hadoop, by Steve Hoffman (Copyright 2013 Packt Publishing)
While the book is focused predominantly on streaming data collected from log files, there is a lot of excellent information on configuring Flume to take advantage of the flexibility it offers. Despite the public perception, there is much more that Flume brings to the table than the scraping of log files.
An excellent introductory reference on Hadoop and Big Data in general is:
Hadoop: The Definitive Guide (Fourth Edition), by Tom White (Copyright 2015 O’Reilly media)
This book not only provides information on Hadoop technologies such as HDFS, Hive, and HBase, but it also provides some good detail on Avro serialization, a technology that proved to be quite useful in practice in environments.
Configuring Flume
As mentioned previously, Flume is incredibly flexible in terms of how it can be configured. Topologies can be arbitrarily complex, supporting fan-in, fan-out, etc. Data streams can be intercepted, modified in flight, and rerouted. There really is no end to what might be configured.
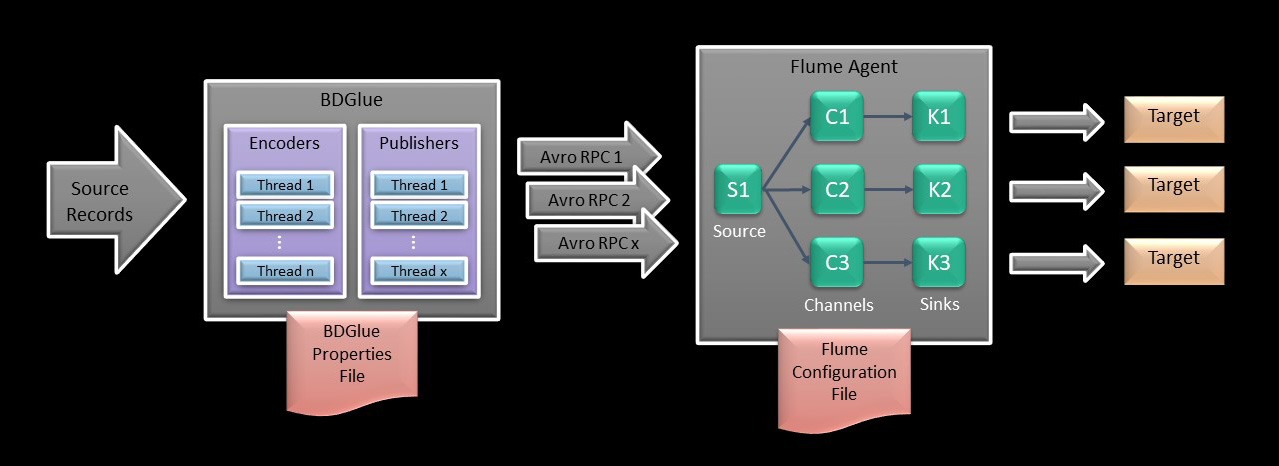
There are two basic topologies for Flume that we feel will be most commonly useful in BDGlue use cases:
A single stream that will handle multiple tables via an agent that consists of a single source-channel-sink combination. This is easiest to implement, and we think will be most common.
A multiplexing stream where a single source fans out into a separate channel and sink for each table being processed. This is more complex to implement, but might be an approach when there are a few high volume tables. There might be a separate channel and sink for each of the high volume tables, and then another “catch all” that handles the rest.
The Flume RPC Client
The BDGlue Flume publisher is implemented to support both Avro and Thrift for RPC communication with Flume. It is possible to switch between the two via a property in the bdglue.properties file. Most of the testing of BDGlue was done using Avro RPCs, and all examples in this user guide leverage Avro for RPC communication. If you wish to use Thrift instead, you will need to configure
bdglue.flume.rpc.type = thrift-rpc in the bdglue.properties file; and
bdglue.sources..type = thrift in the Flume configuration file.
Do not confuse Avro RPC with Avro Serialization, which we also make good use of in BDGlue. While they share a common portion of their name, the two are essentially independent of one another. For the examples in this user guide, we will configure
bdglue.flume.rpc.type = avro-rpc in the bdglue.properties file.
The bdglue.sources..type = avro in the Flume configuration file.
Flume Events
Note that data moves through a Flume Agent as a series of “events”, where in the case of GoldenGate each event represents a captured database operation, or source record otherwise. We’ll just generally refer to the data as “source data” or “source record” going forward. The body of the event contains an encoding of the contents of the source record. Several encodings are supported: Avro binary, JSON, and delimited text. All are configurable via the bdglue.properties file.
In addition to the body, each Flume event has a header that contains some meta-information about the event. For BDGlue, the header will always contain the table name. Depending on other options that are configured, additional meta-information will also be included.
Standard Flume Agent Configuration
As mentioned above, the most typical Flume agent configuration will be relatively simple: a single source-channel-sink combination that writes data to specific destinations for each table that is being processed.
The various “Targets” might be files in HDFS, or perhaps Hive or HBase tables, based on how the properties and configuration files are set up. Our examples in subsequent sections will be based on this configuration and we’ll look at the details of the bdglue.properties and Flume configuration files at that time.
Multiplexing Flume Agent Configuration
Before that, however, we’ll take a quick look at one other configuration that might prove useful. This configuration is one where a single Flume “source” multiplexes data across multiple channels based on table name, and each channel has its own sink to write the data into Hadoop.
To configure in this fashion, you’ll need to specify a separate Flume configuration for each channel and sink. If there are a lot of tables that you want to process individually, this could get fairly complicated in a hurry. The following will give you an idea of what such a configuration file might look like. Note that this example is not complete, but it will give you an idea of what might be required to configure the example above.
# list the sources, channels, and sinks for the agent
bdglue.sources = s1
bdglue.channels = c1 c2 c3
bdglue.sinks = k1 k2 k3
# Map the channels to the source. One channel per table being captured.
bdglue.sources.s1.channels = c1 c2 c3
# Set the properties for the source
bdglue.sources.s1.type = avro
bdglue.sources.s1.bind = localhost
bdglue.sources.s1.port = 41414
bdglue.sources.s1.selector.type = multiplexing
bdglue.sources.s1.selector.header = table
bdglue.sources.s1.selector.mapping.default = c1
bdglue.sources.s1.selector.mapping.<table-1> = c2
bdglue.sources.s1.selector.mapping.<table-2> = c3
# Set the properties for the channels
# c1 is the default ... it will handle unspecified tables.
bdglue.channels.c1.type = memory
bdglue.channels.c1.capacity = 1000
bdglue.channels.c1.transactionCapacity = 100
bdglue.channels.c2.type = memory
bdglue.channels.c2.capacity = 1000
bdglue.channels.c2.transactionCapacity = 100
bdglue.channels.c3.type = memory
bdglue.channels.c3.capacity = 1000
bdglue.channels.c3.transactionCapacity = 100
# Set the properties for the sinks
# map the sinks to the channels
bdglue.sinks.k1.channel = c1
bdglue.sinks.k2.channel = c2
bdglue.sinks.k3.channel = c3
# k1 is the default. Logs instead of writes.
bdglue.sinks.k1.type = logger
bdglue.sinks.k2.type = hdfs
bdglue.sinks.k2.serializer = avro_event
bdglue.sinks.k2.serializer.compressionCodec = gzip
bdglue.sinks.k2.hdfs.path = hdfs://bigdatalite.localdomain/flume/gg-data/%{table}
bdglue.sinks.k2.hdfs.fileType = DataStream
# avro files must end in .avro to work in an Avro MapReduce job
bdglue.sinks.k2.hdfs.filePrefix = bdglue
bdglue.sinks.k2.hdfs.fileSuffix = .avro
bdglue.sinks.k2.hdfs.inUsePrefix = _
bdglue.sinks.k2.hdfs.inUseSuffix =
bdglue.sinks.k3.type = hdfs
bdglue.sinks.k3.serializer = avro_event
bdglue.sinks.k3.serializer.compressionCodec = gzip
bdglue.sinks.k3.hdfs.path = hdfs://bigdatalite.localdomain/flume/gg-data/%{table}
bdglue.sinks.k3.hdfs.fileType = DataStream
# avro files must end in .avro to work in an Avro MapReduce job
bdglue.sinks.k3.hdfs.filePrefix = bdglue
bdglue.sinks.k3.hdfs.fileSuffix = .avro
bdglue.sinks.k3.hdfs.inUsePrefix = _
bdglue.sinks.k3.hdfs.inUseSuffix =
In the example above, note that the configuration for channel/sink c1/s1 is configured as a “default” (i.e. catch all) channel. In this case, we are logging information as an exception. That channel could also be configured to process rather than log those tables, while still allowing “special” handling of channel/sinks c2/k2 and c3/k3.
Running Flume
Once it is actually time to start the flume agent, you’ll do so by executing a statement similar to the following example.
bdglue.conf is the name of your configuration file for Flume. It can have any name you wish.
–name bdglue: “bdglue” is the name of your agent. It must exactly match the name of your agent in the configuration file. You’ll note that each line in the example configuration file above begins with “bdglue”. Your agent can have any name you wish, but this name must match.
–classpath *.jar gives the name of your jar file that contains any custom source-channel-sink code you may have developed. It is not required otherwise. In the case of BDGlue, it will only be needed when delivering to HBase and Oracle NoSQL as custom sink logic was developed for those targets.
Using Flume to Deliver Data into HDFS files
Flume has actually proven to be an excellent way to deliver data into files stored within HDFS. This may seem counterintuitive in some ways, but unless you have an entire file ready to go at once, the idea of streaming data into those files actually makes a lot of sense, particularly if you might have the need to write to multiple files simultaneously. The Flume HDFS “sink” can support thousands of open files simultaneously (say, one for each table being delivered via transactional CDC – change data capture), and provides excellent control over directory structure, and when to roll to a new file based on size, number of records, and/or time.
BDGlue supports delivery to HDFS via Flume in several different encoded file formats:
Delimited text. This is just as it sounds, with column values separated by a delimiter. By default, that delimiter is \001 (^A), which is the default delimiter for Hive, but that can be overridden in the bdglue.properties file.
JSON-formatted text. This is basically a “key-value” description of the data where the key is the name of the column, and the value is the value stored within that column.
Avro binary schema.
Each of these formats was described previously in the section on Encoders.
# list the sources, channels, and sinks for the agent
bdglue.sources = s1
bdglue.channels = c1
bdglue.sinks = k1
#
# Map the channels to the source.
bdglue.sources.s1.channels = c1
#
# Set the properties for the source
bdglue.sources.s1.type = avro
bdglue.sources.s1.bind = localhost
bdglue.sources.s1.port = 41414
bdglue.sources.s1.selector.type = replicating
#
# Set the properties for the channels
bdglue.channels.c1.type = memory
#
# make capacity and transactionCapacity much larger
# (i.e. 10x or more) for production use
bdglue.channels.c1.capacity = 1000
bdglue.channels.c1.transactionCapacity = 100
#
# Set the properties for the sinks
# map the sinks to the channels
bdglue.sinks.k1.channel = c1
#
bdglue.sinks.k1.type = hdfs
bdglue.sinks.k1.serializer = text
#
# each table written to separate directory named ‘tablename’
bdglue.sinks.k1.hdfs.path = hdfs://bigdatalite.localdomain/user/flume/gg-data/%{table}
bdglue.sinks.k1.hdfs.fileType = DataStream
bdglue.sinks.k1.hdfs.filePrefix = bdglue
bdglue.sinks.k1.hdfs.fileSuffix = .txt
bdglue.sinks.k1.hdfs.inUsePrefix = _
bdglue.sinks.k1.hdfs.inUseSuffix =
#
# number of records the sink will read per transaction.
# Higher numbers may yield better performance.
bdglue.sinks.k1.hdfs.batchSize = 10
# the size of the files in bytes.
# 0=disable (recommended for production)
bdglue.sinks.k1.hdfs.rollSize = 1048576
# roll to a new file after N records.
# 0=disable (recommended for production)
bdglue.sinks.k1.hdfs.rollCount = 100
# roll to a new file after N seconds. 0=disable
bdglue.sinks.k1.hdfs.rollInterval = 30
JSON Encoding
Under the covers, when writing to HDFS JSON-encoded data is handled in the same way as delimited text is handled. The fundamental difference is that the data is formatted in such a way that the column names are included along with their contents.
The bdglue.properties file needed for this might look something like the following.
The corresponding Flume configuration file would look the same as it did for delimited text as the data is handled in exactly the same fashion by the Flume agent’s sink when we are writing to HDFS. We will use JSON-formatted data again later to write data into HBase. There will definitely be differences in the configuration files at that point.
# list the sources, channels, and sinks for the agent
bdglue.sources = s1
bdglue.channels = c1
bdglue.sinks = k1
#
# Map the channels to the source.
bdglue.sources.s1.channels = c1
#
# Set the properties for the source
bdglue.sources.s1.type = avro
bdglue.sources.s1.bind = localhost
bdglue.sources.s1.port = 41414
bdglue.sources.s1.selector.type = replicating
#
# Set the properties for the channels
bdglue.channels.c1.type = memory
#
# make capacity and transactionCapacity much larger
# (i.e. 10x or more) for production use
bdglue.channels.c1.capacity = 1000
bdglue.channels.c1.transactionCapacity = 100
#
# Set the properties for the sinks
# map the sinks to the channels
bdglue.sinks.k1.channel = c1
#
bdglue.sinks.k1.type = hdfs
bdglue.sinks.k1.serializer = text
#
# each table written to separate directory named ‘tablename’
bdglue.sinks.k1.hdfs.path = hdfs://bigdatalite.localdomain/user/flume/gg-data/%{table}
bdglue.sinks.k1.hdfs.fileType = DataStream
bdglue.sinks.k1.hdfs.filePrefix = bdglue
bdglue.sinks.k1.hdfs.fileSuffix = .txt
bdglue.sinks.k1.hdfs.inUsePrefix = _
bdglue.sinks.k1.hdfs.inUseSuffix =
#
# number of records the sink will read per transaction.
# Higher numbers may yield better performance.
bdglue.sinks.k1.hdfs.batchSize = 10
# the size of the files in bytes.
# 0=disable (recommended for production)
bdglue.sinks.k1.hdfs.rollSize = 1048576
# roll to a new file after N records.
# 0=disable (recommended for production)
bdglue.sinks.k1.hdfs.rollCount = 100
# roll to a new file after N seconds. 0=disable
bdglue.sinks.k1.hdfs.rollInterval = 30
Having the metadata transmitted with the column data is handy, but it does take up more space in HDFS when stored this way.
Configuring for Binary Avro Encoding
As mentioned earlier, and advantage to Avro encoding over JSON is that it is more compact, but it is also a little more complex as Avro schema files are required. It is possible to have BDGlue generate Avro schema files on the fly from the metadata that is passed in from the source, but this is not recommended as the files are needed downstream before data is actually landed. Instead, it is recommended that for data coming from relational database sources you utilize the SchemaDef utility to generate these schemas. See Generating Avro Schemas with SchemaDef later in this document for more information on how to do this.
Once we have the Avro schema files where we need them, we can think about configuring BDGlue and Flume to handle Avro encoded data.
The first step, as before, is to set the appropriate properties in the bdglue.properties file. You will see here that we are introducing a couple of new properties associated with the location of the *.avsc files locally and in HDFS.
# configuring BDGlue for Avro encoding
#
bdglue.encoder.class = bdglue2.encoder.AvroEncoder
bdglue.encoder.threads = 2
bdglue.encoder.tx-optype = false
bdglue.encoder.tx-timestamp = false
bdglue.encoder.user-token = false
#
bdglue.event.header-optype = false
bdglue.event.header-timestamp = false
bdglue.event.header-rowkey = true
bdglue.event.header-avropath = true
# The URI in HDFS where schemas will be stored.
# Required by the Flume sink event serializer.
bdglue.event.avro-hdfs-schema-path = hdfs:///user/flume/gg-data/avro-schema/
# local path where bdglue can find the avro *.avsc schema files
bdglue.event.avro-schema-path = /local/path/to/avro/schema/files
#
bdglue.publisher.class = bdglue2.publisher.flume.FlumePublisher
bdglue.publisher.threads = 2
bdglue.publisher.hash = rowkey
#
bdglue.flume.host = localhost
bdglue.flume.port = 41414
bdglue.flume.rpc.type = avro-rpc
And of course, we also need to configure Flume to handle this data as well. Again, you’ll see some differences in the properties for the agent’s sink … specifically a non-default serializer that properly creates the *.avro files with the proper schema.
# list the sources, channels, and sinks for the agent
bdglue.sources = s1
bdglue.channels = c1
bdglue.sinks = k1
#
# Map the channels to the source. One channel per table being captured.
bdglue.sources.s1.channels = c1
#
# Set the properties for the source
bdglue.sources.s1.type = avro
bdglue.sources.s1.bind = localhost
bdglue.sources.s1.port = 41414
bdglue.sources.s1.selector.type = replicating
#
# Set the properties for the channels
# c1 is the default ... it will handle unspecified tables.
bdglue.channels.c1.type = memory
#
# make capacity and transactionCapacity much larger
# (i.e. 10x or more) for production use
bdglue.channels.c1.capacity = 1000
bdglue.channels.c1.transactionCapacity = 100
#
# Set the properties for the sinks
# map the sinks to the channels
bdglue.sinks.k1.channel = c1
#
bdglue.sinks.k1.type = hdfs
bdglue.sinks.k1.serializer = org.apache.flume.sink.hdfs.AvroEventSerializer$Builder
#
bdglue.sinks.k1.hdfs.path = hdfs://bigdatalite.localdomain/user/flume/gg-data/%{table}
bdglue.sinks.k1.hdfs.fileType = DataStream
# avro files must end in .avro to work in an Avro MapReduce job
bdglue.sinks.k1.hdfs.filePrefix = bdglue
bdglue.sinks.k1.hdfs.fileSuffix = .avro
bdglue.sinks.k1.hdfs.inUsePrefix = _
bdglue.sinks.k1.hdfs.inUseSuffix =
#
# number of records the sink will read per transaction.
# Higher numbers may yield better performance.
bdglue.sinks.k1.hdfs.batchSize = 10
# the size of the files in bytes.
# 0=disable (recommended for production)
bdglue.sinks.k1.hdfs.rollSize = 1048576
# roll to a new file after N records.
# 0=disable (recommended for production)
bdglue.sinks.k1.hdfs.rollCount = 100
# roll to a new file after N seconds. 0=disable
bdglue.sinks.k1.hdfs.rollInterval = 30
And that’s it. We are now all set to deliver Avro encoded data into *.avro files in HDFS.
Making Data Stored in HDFS Accessible to Hive
So now we have built and demonstrated the foundation for what comes next … making the data accessible via other Hadoop technologies. In this section, we’ll look at accessing data from Hive.
You may be wondering why we went to the trouble we did in the previous section. It certainly seems like a lot of work just to put all that data into HDFS. The answer to that question is: “Hive.” It turns out that once data has been properly serialized and stored in Avro format, Hive can make use of it directly … no need to Sqoop the data into Hive, etc. By approaching things this way, we save both an extra “Sqoop” step, and we eliminate any potential performance impact of writing the data directly into Hive tables on the fly. Of course, you can always choose to import the data into actual Hive storage later if you wish.
Configuration
The configuration for doing this is exactly the same as we did in the previous section. Since there are no differences in the Flume configuration, so we won’t repeat it here. There are no differences in the bdglue.properties file either. We are repeating it here to highlight one property. The value of this property must match the corresponding value specified by the SchemaDef utility when generating the Hive Query Language DDL for the corresponding tables.
# configuring BDGlue to create HDFS-formatted files that
# can be accessed by Hive.
#
bdglue.encoder.class = bdglue2.encoder.AvroEncoder
bdglue.encoder.threads = 2
bdglue.encoder.tx-optype = false
bdglue.encoder.tx-timestamp = false
bdglue.encoder.user-token = false
#
bdglue.event.header-optype = false
bdglue.event.header-timestamp = false
bdglue.event.header-rowkey = true
bdglue.event.header-avropath = true
# The URI in HDFS where schemas will be stored.
# Required by the Flume sink event serializer.
bdglue.event.avro-hdfs-schema-path = hdfs:///user/flume/gg-data/avro-schema/
# local path where bdglue can find the avro *.avsc schema files
bdglue.event.avro-schema-path = /local/path/to/avro/schema/files
#
bdglue.publisher.class = bdglue2.publisher.flume.FlumePublisher
bdglue.publisher.threads = 2
bdglue.publisher.hash = rowkey
#
bdglue.flume.host = localhost
bdglue.flume.port = 41414
bdglue.flume.rpc.type = avro-rpc
Accessing *.avro Files From Hive
Hive is smart enough to be able to access *.avro files where they live, and in this section we’ll show you how that works.
The first, and only real step, is to create a table in Hive and tell it to read data from *.avro files. You’ll notice a couple of key things:
We do not need to specify the columns, their types, etc. All of this information is found in the Avro schema metadata, so all we have to do is point Hive to the schema and we’re all set.
This process is making use of Hive’s Avro SerDe (serializer and deserializer) mechanism to decode the Avro data.
What is especially nice is that we can use the SchemaDef utility to generate the Hive table definitions like the following example. See Generating Hive Table Definitions for Use with Avro Schemas for more information.
-- drop the table
DROP TABLE CUST_INFO;
-- now create the table using the avro schema
CREATE EXTERNAL TABLE CUST_INFO
COMMENT "A table backed by Avro data with the Avro schema stored in HDFS"
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.avro.AvroSerDe'
STORED AS
INPUTFORMAT 'org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat'
LOCATION '/user/flume/gg-data/bdgluedemo.CUST_INFO/'
TBLPROPERTIES (
'avro.schema.url'=
'hdfs:///user/flume/gg-data/avro-schema/bdgluedemo.CUST_INFO.avsc'
);
And as a validation that this all works as expected, review the following.
hive> describe CUST_INFO;
OK
Id int from deserializer
Name string from deserializer
Gender string from deserializer
City string from deserializer
Phone string from deserializer
old_id int from deserializer
zip string from deserializer
cust_date string from deserializer
Time taken: 0.545 seconds, Fetched: 8 row(s)
hive> select * from CUST_INFO limit 5;
OK
1601 Dane Nash Male Le Grand-Quevilly (874) 373-6196 1 81558-771 2014/04/13
1602 Serina Jarvis Male Carlton (828) 764-7840 2 70179 2014/03/14
1603 Amos Fischer Male Fontaine-l'Evique (141) 398-6160 3 9188 2015/02/06
1604 Hamish Mcpherson Male Edmonton (251) 120-8238 4 T4M 1S9 2013/12/21
1605 Chadwick Daniels Female Ansfelden (236) 631-9213 5 38076 2015/04/05
Time taken: 0.723 seconds, Fetched: 5 row(s)
Hive>