GoldenGate as a Source
When linked with BDGlue, the GoldenGate Java Adapter becomes a fully functional GoldenGate Adapter that will deliver database operations that have been captured by Oracle GoldenGate from a relational database source into various target “Big Data” repositories and formats. Target repositories include HDFS, Hive, HBase, Oracle NoSQL, and others supported by BDGlue.
BDGlue is intended as a starting point for exploring Big Data architectures from the perspective of real-time change data capture (CDC) as provided by GoldenGate. As mentioned in the introduction, Hadoop and other Big Data technologies are by their very natures constantly evolving and infinitely configurable.
A GoldenGate Java Adapter is referred to as a “Custom Handler” in the GoldenGate Java Adapter documentation. This “custom handler” integration with BDGlue is developed using GoldenGate’s Java API.
A custom handler is deployed as an integral part of a GoldenGate REPLICAT process. The REPLCIAT and the custom handler are configured through a REPLICAT parameter file and the adapter’s properties file. We will discuss the various properties files in more detail later in this document.
The REPLICAT process executes the adapter in its address space. The REPLICAT reads the trail file created by the GoldenGate EXTRACT process and passes the transactions into the adapter. Based on the configuration in the properties file, the adapter will write the transactions in one of several formats. Please refer to the Oracle GoldenGate Adapters Administrator’s Guide for Java (which can be found on http://docs.oracle.com) for details about the architecture and developing a custom adapter.
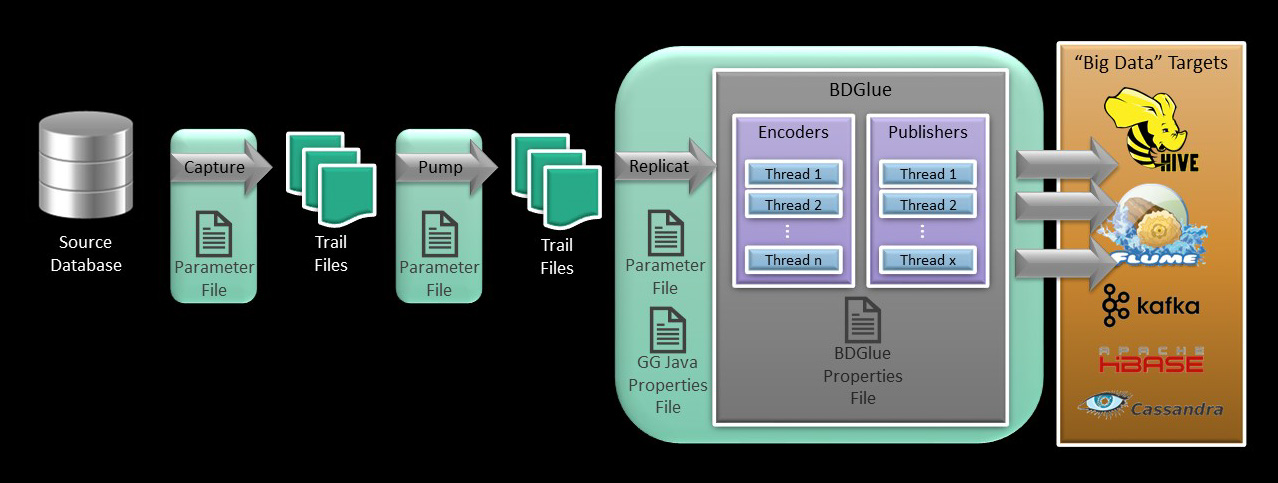
Configuring GoldenGate for BDGlue
There are three basic steps to getting GoldenGate properly configured to deliver data to BDGlue:
- Configure GoldenGate to capture the desired tables from the source database and write them to a trail file.
- Configure the rest of the GOldenGate “pipeline” as required to route the data in the GoldenGate trail files where it needs to go.
- Configure the REPLCIAT process to reference the trail files and execute the Java Adapter.
Configure the GoldenGate EXTRACT
This User Guide makes no attempt to explain details of configuring GoldenGate itself. Please refer to the GoldenGate documentation for that information.
Simplistically speaking, however, a GoldenGate EXTRACT process has a parameter file that tells GoldenGate how to log into the source database to obtain table metadata, and what tables it should be concerned about capturing.
Here is a very basic example of a parameter file for connecting to a MySQL source database. The most important things to note are the tables we care about and the fact that there is nothing specific to configuration of the Java Adapter found there.
EXTRACT erdbms
DBOPTIONS HOST localhost, CONNECTIONPORT 3306
SOURCEDB bdgluedemo, USERID root, PASSWORD welcome1
EXTTRAIL ./dirdat/tc
GETUPDATEBEFORES
NOCOMPRESSDELETES
TRANLOGOPTIONS ALTLOGDEST /var/lib/mysql/log/bigdatalite-bin.index
TABLE bdgluedemo.MYCUSTOMER;
TABLE bdgluedemo.CUST_INFO;
TABLE bdgluedemo.TCUSTORD;
Please do make note of the parameters “GETUPDATEBEFORES” and “NOCOMPRESSDELETES”. If you think about it, in most cases it wouldn’t make sense to propagate a partial record downstream in the event of an update or a delete operation in the source database when dealing with Big Data targets. These parameters ensure that all columns are propagated downstream even if they are unchanged during an update operation on the source, and that all columns are propagated along with the key in the case of a delete.
Configure the GoldenGate REPLICAT
Unlike the EXTRACT, there are things specific to the Java Adapter found in the parameter file for the REPLICAT. This is because the Java Adapter is invoked by and runs as a part of the REPLICAT process.
What follows is a simple REPLICAT parameter file. There are several things to note there:
- The TARGETDB LIBFILE libggjava.so SET property=dirprm/ggjavaue.properties parameter which tells GoldenGate to invoke the Java adapter (libggjava.so) and also identifies the name of the properties file to process for java-related configuration information.
- The actual tables that this REPLICAT will be delivering. Simplistically, this might be the same as the tables specified in the EXTRACT, but in more complicated environments it is possible that we might configure multiple REPLICATs, each handling a subset of the tables we are capturing.
REPLICAT ggjavaue
--
TARGETDB LIBFILE libggjava.so SET property=dirprm/ggjavaue.properties
--
--REPORTCOUNT EVERY 1 MINUTES, RATE
--GROUPTRANSOPS 1000
--
MAP bdgluedemo.*, TARGET bdgluedemo.*;
The Java Adapter itself has a properties file that has a bunch of configuration information that the Java Adapter needs to get going. Most of the information is fairly generic to the Java adapter itself and how it executes. The properties file resides in the GoldenGate “dirprm” directory along with the parameters for the various GoldenGate processes (called ggjavaue.properties above). By default, GoldenGate assumes that the name of the properties file is based on the name of the GoldenGate process it is associated with. In this case, the REPLICAT process is an instance of the Java Adapter called “ggjavaue”. The parameter file for the process is called “ggjavaue.prm”, and the properties file shown below would be called “bdglue.properties.” Note that you have the flexibility to set the properties file name to anything you wish by making use of the SET parameter … instead of ggjavaue.properties as described above, you could chose to SET the name to “myprocess.properties” for example.
TARGETDB LIBFILE libggjava.so SET property=dirprm/myprocess.properties
Here is an example of a properties file that my represent ggjavaue.properties:
# Adapter Logging parameters.
#gg.log.logname=log4j
#gg.log.tofile=true
# gg.log.level = [ info | debug | trace ]
gg.log.level=INFO
gg.log=log4j
#
goldengate.userexit.timestamp=utc
goldengate.userexit.writers=javawriter
#
# Properties for reporting statistics
# Minimum number of {records, seconds} before generating a report
javawriter.stats.time=360
javawriter.stats.numrecs=500
javawriter.stats.display=TRUE
javawriter.stats.full=TRUE
#
# generate a report every N seconds
#gg.report.time=30sec
#
javawriter.bootoptions= -Xms64m -Xmx512M -Dlog4j.configuration=ggjavaue-log4j.properties -Dbdglue.properties=./gghadoop/console-publisher.properties -Djava.class.path=./gghadoop:./ggjava/ggjava.jar
#
gg.classpath=dirprm:./gghadoop/lib/*:./gghadoop/lib/dependencies/*
#
gg.handlerlist = bdglue
gg.handler.bdglue.type=bdglue2/source/gghadoop/GG12Handler
gg.handler.bdglue.mode=op
There are a number of things to make specific note of:
- -Dbdglue.properties=./gghadoop/bdglue.properties. This defines a Java “system property” that the GoldenGate BDGlue “source” is looking for so that it can locate a properties file that is specific to what it needs to configure itself to run. If the system property is not defined, BDGlue will look for a file called bdglue.properties somewhere in a directory pointed to by the Java classpath. If the system property is used, calling the properties file “bdglue.properties” is not strictly required.
- gg.handlerlist=bdglue gives a name to handler which is then used to identify properties to pass into it
- gg.handler.gghadoop.type=bdglue2/source/gghadoop/GG12Handler identifies the class that is the entry point into BDGlue. [Note: at present, the GG12Handler supports the GoldenGate 12.2 and later releases of GoldenGate for Big Data.]
- gg.handler.gghadoop.mode=op sets the Java Adapter to “operation mode” (rather than transaction mode) which is most appropriate for Big Data scenarios. Since all data in the trail file has been committed, this “eager” approach is more efficient.
- gg.classpath=./gghadoop/lib/* points to a directory containing all of the Java dependencies for compiling and running BDGlue.
Here is a sample properties file that provides configuration properties for BDGlue:
# configure BDGlue properties
bdglue.encoder.threads = 3
bdglue.encoder.class = bdglue2/encoder/JsonEncoder
#
bdglue.event.header-optype = true
bdglue.event.header-timestamp = true
bdglue.event.header-rowkey = true
#
bdglue.publisher.class = bdglue2/publisher/flume/FlumePublisher
bdglue.publisher.threads = 2
bdglue.publisher.hash = rowkey
#
bdglue.flume.host = localhost
bdglue.flume.port = 5000
bdglue.flume.rpc.retries = 5
bdglue.flume.rpc.retry-delay = 10
We won’t go into details on the contents of this file here as they will vary a fair amount depending on what the target of BDGlue is: HDFS, Hive, HBase, NoSQL, etc. We’ll look at specific configurations in more detail subsequent sections of this document.
Prerequisite Requirements
Be sure you have taken care of the following before attempting to run the GoldenGate Java Adapter:
- Download, install and configure GoldenGate to capture from the source database.
- Configure GoldenGate to capture all columns (uncompressed updates and deletes). This will some additional overhead to the capture process and require additional space in the trail files, but will eliminate the need to have to do any downstream reconciliation in the Hadoop environment later.
- Download, install, and configure the current version of GoldenGate for Big Data (version 12.3.x or later).
- This obviously requires Java to be installed and available in the GoldenGate environment. If it is not present, you will have to download and install it separately. The GoldenGate Java adapter requires Java SE 1.8 or later. BDGlue was built with Java SE 1.8. It is recommended that you use that version of Java. Refer to the documentation for the GoldenGate Java adapter and GoldenGate for Big Data for more information.
- Identify the target technology that you will be delivering data to, and ensure that the latest version of that technology has been installed and configured. You will likely need to know:
- The host name and port number to which BDGlue will connect
- The directory path where GoldenGate will write data if delivering to HDFS.
- The directory path where we will place the Avro schema files in the HDFS environment if you will be configuring for Avro serialization.